
我们也可以手动构建查询条件,手动实现nextToken分页条件。即使你不熟悉nextToken分页和ES查询的具体用法,你也应该能做出以下判断◆◆★◆◆:你一定可以用ES的查询条件实现任意的nextToken分页逻辑■◆◆★◆■。理由是ES的Bool查询具有逻辑完备性。
过滤(Filtering):过滤掉特殊字符,例如移除特定字符、删除数字替换等。
这样做的好处是★◆★■◆◆,如果项目中涉及到多种数据库的分页,则后端代码的分页逻辑可以共用,只需要在不同的数据库中实现相同的nextToken条件:
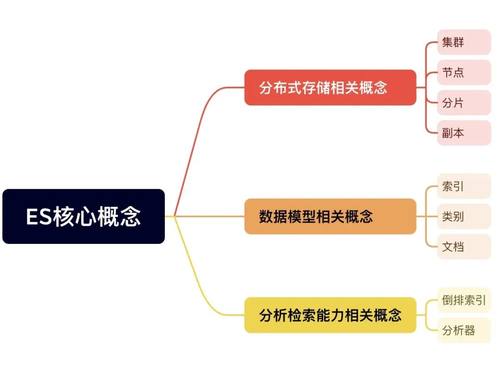
Elasticsearch(ES)是一种基于分布式存储的搜索和分析引擎,目前在许多场景得到了广泛使用,比如和github的检索,使用的就是ES■★◆。ES中不乏纷繁冗余的细节,而本文将关注其核心特性:分布式存储特性和分析检索能力◆★■◆★。围绕这两大核心特性,本文将介绍其中的概念、原理与实践案例,希望让读者快速理解ES的核心特性与应用场景。
分词(Tokenization):将文本拆分成单词■◆◆◆,对于英文,以空格为分界线来拆分单词■◆。
分析器是Elasticsearch用于进行文本预处理的组件。它的主要作用是将文本转化为可被倒排索引的单词(term)。分析通常由以下几个步骤组成★■■■◆:
正排索引是从文档到关键字的映射(已知文档求关键字),倒排索引是从关键字到文档的映射(已知关键字求文档)。倒排索引由两个主要部分组成:词汇表(Vocabulary)和倒排列表(Inverted List)★■■★◆★。词汇表存储了所有不同的单词,而倒排列表存储了每个单词文档中的分布情况。
受制于单个ES节点的性能上限(内存★■■、磁盘IO速度),如果数据以整块形式进行存储与管理,则无法足够快速地响应客户端的请求,因此ES将索引拆分为更小块的分片,以便分布式存储和并行处理数据。
带编辑距离的term查询。具体实现■◆◆:给定一个模糊度(编辑距离),ES会根据这个编辑距离,对原始的单词进行拓展■★★★★◆,生成一系列候选的新单词★◆。对每一个编辑距离内的新单词★◆◆■★,做term查询。
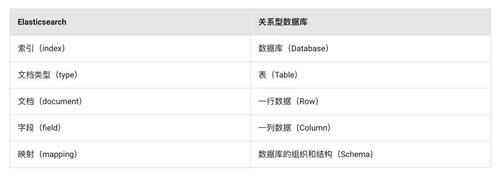
索引中的每一条数据叫作一个文档★★,它是一个JSON格式的数据对象。对应关系型数据库中的数据行公海赌船大爆奖。这一点与非关系型数据库MongoDB很类似,MongoDB属于文档数据库,每条数据也是一个BSON文档(BinaryJSON)。非关系型数据库的文档相比关系型数据库的数据行★◆◆■■★,优势在于提供了更高的自由度★★★■■■,文档中可以方便地新增减字段,多个文档间也不要求字段完全一致。同时,文档也保留了一部分结构化存储的特性◆★,对存储的数据进行了一定的结构化封装,而没有像K-V非关系型数据库那样完全抛弃数据的结构化。
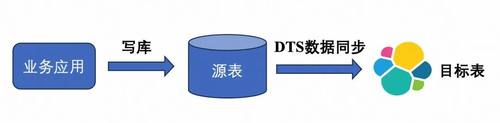
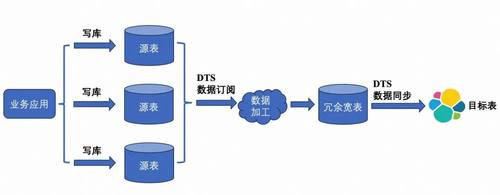
是阿里云提供的一种云服务产品■■,基于binLog模拟主从复制实现数据同步。一对一数据同步方便高效,但对多表JOIN场景无法支持。如果表结构出现变更,则需要手动删除目标ES库,重建同步任务★■。
标准化(Normalization):对单词进行规范化,通常包括大小转小写、去除停用词等■◆★■■。
在阿里云DTS数据同步工具中■★◆,可以选择一系列ES内置的分析器,但是Elasticsearch的内置分析器对于中文的支持较差★■★■◆,采取了暴力拆分每个中文单字的策略◆◆■■。如果希望对中文进行合适的分词,可以选择第三方分词器■◆★,比如jieba分词器。
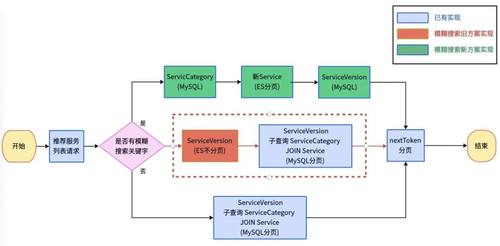
在上述项目中,一个API服务使用到了两条查询链路:一条纯MySQL的查询链路,另一条ES分页+MySQL补字段的查询链路◆★◆。由于在ES分页中■■★,我们已经手动复现了MySQL中的nextToken分页条件。因此,在查询结束后,封装nextToken分页请求的这部分后端逻辑就可以实现复用◆★◆。如果MySQL基于自实现的nextToken分页而ES使用官方推荐的Sort分页◆★◆,则复用性较差,需要两套分页逻辑。
类别在较早的Elasticsearch版本中,一个索引可以包含多个类别,每个类别用于存储不同种类的文档。对应关系型数据库中的数据表◆◆。然而◆★■,在Elasticsearch 7.0以后★★,类别逐渐被弃用◆■◆■■。原因是同一索引下,不同type的数据存储其他type的field◆★★,包含大量空值,造成资源浪费◆◆■■■■。
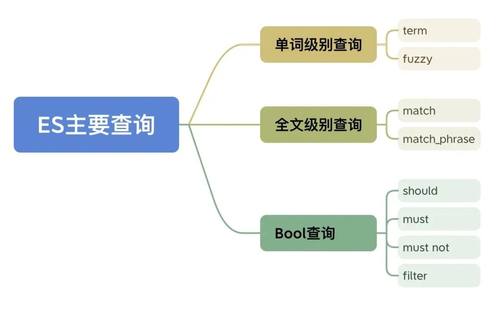
基于以上的核心概念,Elasticsearch通过分布式存储结构和分析检索能力■★◆■★,支持并提供了多种不同类型的查询能力,用于满足各种检索需求。以下是ES中主要的查询类型:
在ES中,内置的分页机制为sort+Search After分页。它会对每次请求生成一个游标字段◆■★◆■★,这就相当于标记了上一页的结束位置,因此下次请求只要从上一次的游标字段开始,就能够方便地查找下一页。这实际上是ES官方提供的一种nextToken分页实现,它省略掉了构建游标这一过程,只需要使用者在查询条件中给定排序字段。
像使用match和match_phrase这样的高层查询都属于全文级别查询◆■◆★★★,全文级别查询是对多个/多种单词级别查询的封装■◆★★■■。
拓展:如果涉及不同数据库之间的关联查询,也可以采用此方案◆◆,比如用ES处理有限的文本字段★★,查得一个id列表★■■,然后把这个id列表给MySQL的完整查询作为条件,补齐剩下的字段。
窄表★◆:严格按照数据库设计三范式设计的数据表。这种表的设计形式减少了数据冗余★■★◆,但是实现一个复杂查询要使用很多张表■★★◆◆■,涉及多表JOIN问题,可能会影响性能★◆■★。其特点是方便扩展★■★◆■,多个窄表可以组合并适应多种业务场景◆■★,无论有多少不同的场景■■★■◆,都不用修改原本的表结构。但在查询逻辑和代码逻辑上需要进行封装。
节点就是单个的Elasticsearch实例★◆■◆,该实例运行的载体可以是物理服务器或虚拟机器。
在match查询的基础上,保证输入的单词之间的顺序不变才会命中◆◆◆★■,性能相比match会差一些。
ES与非关系型的文档数据库类似,基于文档存储数据,没有固定的表结构。关系型数据库以二维表结构的形式来组织数据■★★◆★◆,并擅长提供对数据表间关系的管理。而ES以文档为数据的组织形式,进行扁平化存储,它不擅长进行关系管理而擅长对扁平化的文档进行文本检索。
ii.分析查询字符串■■★■◆,将输入字符串进行分词,对分出来的每个单词★◆★,根据是否设置了模糊度参数fuzziness,选择走term query或者fuzzy query◆■★■◆;
倒排索引是Elasticsearch中用于高效检索文档的关键数据结构◆■★◆■。它是将文档中的每个单词映射到包含它的文档上。这种数据结构使得Elasticsearch能够高效地处理文本信息这类非结构化数据◆◆★◆,相比传统关系型数据库的正排索引遍历整个数据表◆◆★◆■★,它能够高效地进行文本检索与分析★★。
如果我们搭建一个中间层,将多表JOIN结果先写入一个冗余的MySQL宽表,再同步到ES◆■,则数据同步可以使用简单高效的DTS。代价是整个同步链路环节增多★★■★,不稳定性增加了★★◆◆■■。
由于ES擅长检索而不是存储,业务场景中很少会以ES作为主力做数据存储■★◆,而是使用关系型数据库进行存储,在需要ES时再构建需要的数据并进行同步。具体来说,有手动写入和数据同步工具等方案。
在服务端开发的实践中◆◆■◆★★,由于数据量大,不可能一次请求一次查询就返回全部数据。因此,对数据进行分页查询是一种常见的工程实践。而由于ES方便处理非结构化字段的能力,常常被用作搜索框API中的主力分页查询。
是ES官方套件系列中的数据同步工具。支持在config配置文件中写入需要的SQL逻辑并存储为视图,并通过视图来写入多表查询的结果到ES。这种方式自由度较高,能够方便地构建所需要的数据■■■■★。但是数据同步的性能略差(秒级别)。
宽表:通俗地讲就是字段很多的数据库表。指的是把特定的查询业务需求所需要的全部字段都关联在一起的一张数据库表。由于关联了大量冗余字段★◆■◆◆,宽表已经不符合数据库设计的三范式★◆,而因此获得的好处就是查询性能的提高与关联查询的简化(避开了查询时JOIN)公海赌船大爆奖。这是一种典型的空间换时间的优化思路。但宽表不便扩展,如果业务需求有变化,哪怕是需要新增一个字段,都需要变更宽表。
在ES中,由于其分布式存储特性和非关系性数据模型,类似关系型数据库中JOIN联表查询这样的操作将非常不便★◆★。ES内置了类似MySQL的JOIN的关联查询实现:父子文档,但它存在功能和性能上的限制◆■★★■:父子文档需要在在同一个分片中,额外实现关系管理需要的成本。ES官方通常不建议使用这种方式★◆◆◆。
如果给定了模糊度参数fuzziness★■,match在单词级别查询上会调用fuzzy querry;如果未给定此参数,则match在单词级别上会走term query;
1◆■★■◆■.如果analyzed◆◆★,说明该字段已经被分析器处理过,match会对输入进行分词;2.如果not_analyzed■■■,说明该字段未被分析器处理过★■★,match走完全匹配;
坏处■★:数据量大时◆★,两次查询会带来额外的开销,因为每次查询都需要建立连接、发送请求...◆◆...
在已有的业务逻辑中★■,同步或异步地增加对ES的增删改查◆◆■★■◆。实现简单,但不利于扩展,耦合性较强◆★■★。
filter:可以用于作为查询中的前置过滤条件★★,must类似,好处是它不会参与计算相关性分数。
在ES中,如果要实现关联查询,实践一般为构建宽表或采取服务端JOIN这种折中方案。
每个分片可以有零个或者多个副本,副本与分片对外都可以提供数据查询服务■★。副本的存在可以增加整个ES系统的高可用性,高并发性,因为分片能做到的事情,副本也能做到。计算机世界里没有银弹,副本的开销主要体现在数据同步成本的增加(每次数据更新时,都需要把分片上的数据变更同步到其他副本中)。
集群是一组运行在不同载体(物理或虚拟机器)上的一个或多个Elasticsearch节点的集合。在集群内,节点间相互合作,对数据进行存储和管理。
IDF(inverse document frequency)■◆★◆■★:反向文档频率。 表示单词在整个文本集合中出现的频率(有多少文本包含了这个词)的倒数◆■■■◆★,IDF越大表示该词的重要性越高◆■,反映了单词是否具有distinguish其所在文本的能力。
TF(term frequency):词频。表示单词在该文本中出现的频率(单词在该文本中出现的多不多);
ES中分两个索引来存储数据,查询时在服务端的业务代码内进行两次查询,将第一次查询的结果作为第二次查询的条件■■。
最基础的ES查询,把输入字符串全部看作一个完整的单词,然后去倒排索引表里面找★★■◆★★。
索引由一个或多个分片组成。索引是Elasticsearch中的顶层数据容器◆■★,对应关系型数据库中的数据库模型公海赌船大爆奖。

根据要求,各单位登录全国数据资源调查管理平台,填报相关调查表。全国数据资源调查工作开展时间为2024年2月18日00:00至3月5日24:00■。
六大行集体宣布,明起调整!未来房贷利率加点幅度如何动态调整?未来重定价周期如何选择? 郭谨一公开回应■“瑞幸计划登陆美国市场”:公司积极探索在美业务,无重
2024年10月25日,新三板创新层公司源通机械(430717,收盘价:2.83元)发生一笔大宗交易中国公海赌船,成交价2元/股,成交数量22■.36万股,
邮轮游艇企业可享受的利好政策:《三亚市鼓励邮轮旅游产业发展财政奖励实施办法》以及《海南邮轮港口海上游航线试点实施方案》。 A■:注册公司目
6月17日,长城电工600192)发布股票交易风险提示公告,公司股票于2024年6月13日至6月17日连续三个交易日涨停,累计涨幅约为30%,但公司
8月7日晚间,新三板多家挂牌公司发布公告■,以下是同壁财经整理的重要公告: 8月7日,志达精密披露申请全国股转公司挂牌的第一轮问询回复■,
3.请各单位做好放假期间的安全稳定、保密及应急管理工作,主要负责手机要保持24小时畅通欢迎公海来到赌船710。 中秋、国庆双节将至■,根据
本公司董事会及全体董事保证本公告内容不存在任何虚假记载、误导性陈述或者重大遗漏■,并对其内容的真实性、准确性和完整性承担法律责任。 本公司
因赛集团公告,公司拟通过发行股份及支付现金的方式向刘焱、宁波有智青年投资管理合伙企业(有限合伙)、黄明胜、韩燕燕、于潜购买其合计持有的智者品牌80%股权。标
中国证监会4月发布《5项资本市场对港合作措施》,支持内地头部企业赴港上市融资。内地企业从A股转战香港上市的步伐加快。随着更多内地企业赴港上市,IPO
苏州通锦精密工业股份有限公司(简称苏州通锦或通锦),成立于2002年,专业伺服电动缸厂家,位于苏州国家级高新技术开发区,专注于研发、设计、组装、销售主营无人车间、自动生产线、黑灯工厂、伺服电缸、伺服电动缸、智能伺服压装机、第七轴机器人、桁架、地轨及相关自动化部件业务。公司已于2016年5月18日正式在全国中小企业股份转让系统挂牌,证券代码:837453。
公司地址:苏州高新区建林路411号
电话:0512-68416781
传真:0512-66673556
E-mail:sales@sztongjin.com

关注通锦 · 更多干货资讯